目录
1、原始字符串‘r’
2、字符转换问题
3、open与write函数’wb’与’w’区分
4、Python里面\与\\的区别
1、原始字符串‘r’
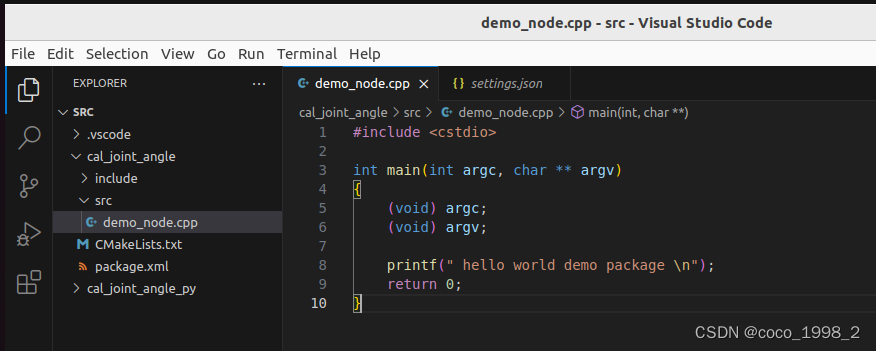
以前的脚本通过Python2.7写的,通过Python3.12去编译发现不通用了,其实也是从一个初学者的角度去看待这些问题。
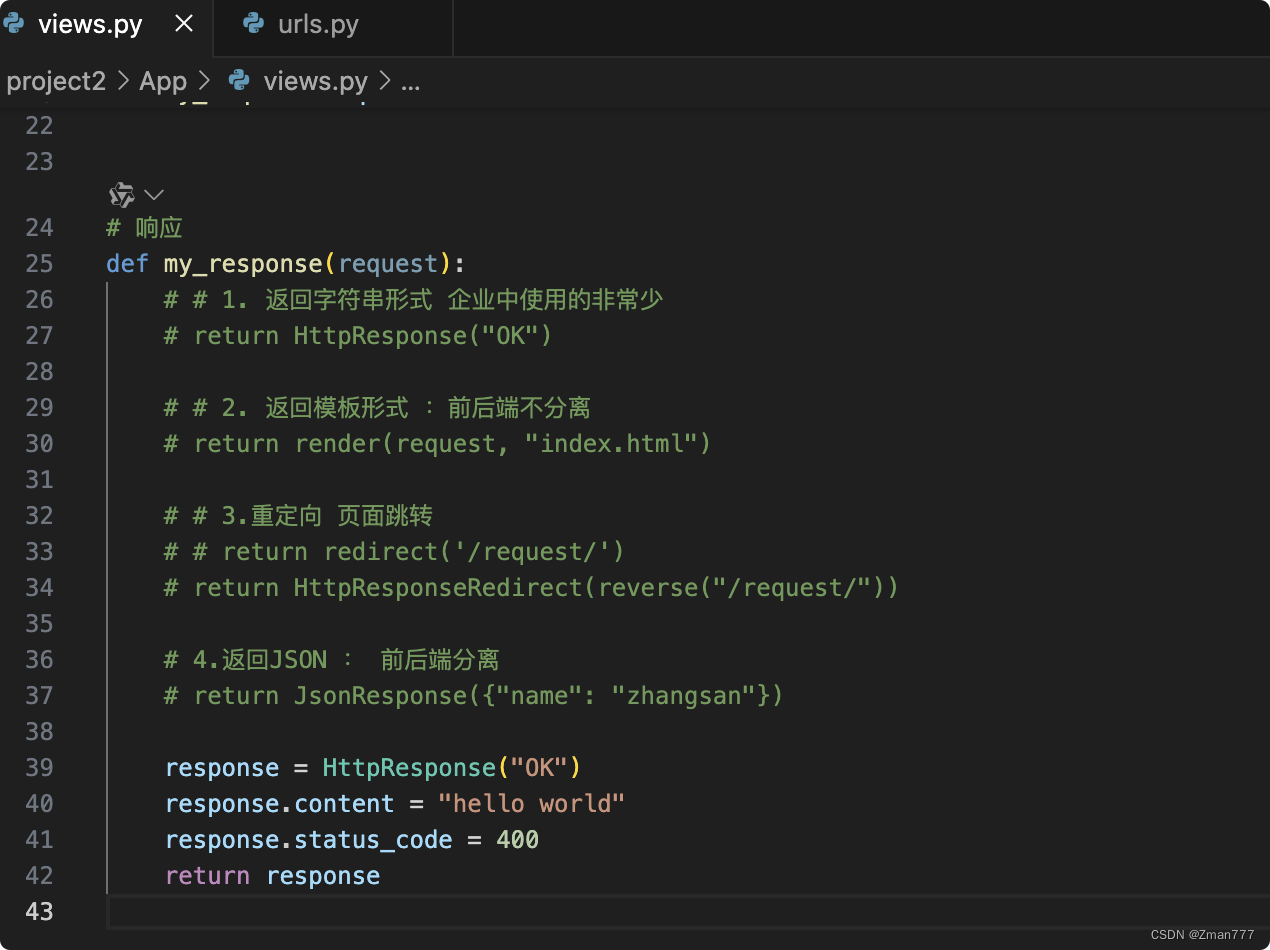
其中的\被认为特殊字符串的一个标识,如下图
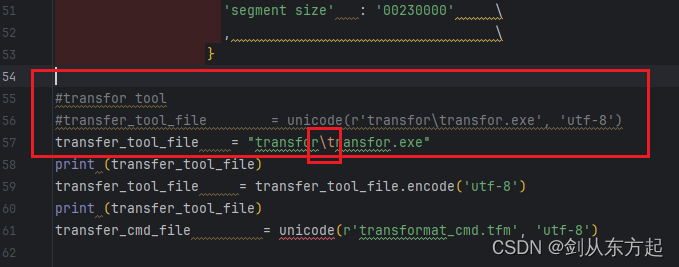
需要在前面加个“r”才被认为原始字符串。

2、字符转换问题
先辨别两个概念:
encode()方法将字符串对象转换为字节序列。这通常用于将Unicode字符串转换为可以在文件系统中存储或通过网络传输的字节流。默认情况下,Python使用UTF-8编码,但你可以指定其他编码格式。
# 将字符串转换为UTF-8编码的字节序列
original_string = '你好,世界'
encoded_string = original_string.encode('utf-8')
print(encoded_string) # 输出: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'decode()方法则是将字节序列转换回字符串对象。这在你从文件系统读取数据或接收网络传输数据时非常有用,需要将字节流转换回可读的字符串形式。
# 将UTF-8编码的字节序列解码回字符串
encoded_string = b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'
decoded_string = encoded_string.decode('utf-8')
print(decoded_string) # 输出: '你好,世界'简而言之,encode()用于将字符串编码为字节序列,而decode()用于将字节序列解码为字符串。在Python 3.x中,所有字符串默认都是Unicode字符串,因此编码和解码操作通常与处理非ASCII字符集相关。
3、open与write函数’wb’与’w’区分
梳理一个概念
'w'(写模式):
如果文件不存在,会创建一个新文件。
如果文件已存在,会覆盖原有内容。
打开文件后,可以直接写入字符串数据。
'wb'(二进制写模式):
如果文件不存在,同样会创建一个新文件。
如果文件已存在,也会覆盖原有内容。
打开文件后,必须写入字节数据,而不是字符串。这通常用于写入非文本文件,如图片或其他二进制文件。
在Windows系统中,使用'w'模式写入文件时,Python会将换行符\n自动转换为\r\n。而在'wb'模式下,Python不会做这种转换,写入的内容完全由程序员控制
例如,如果你想写入一行文本,使用'w'模式:
with open('example.txt', 'w') as file:
file.write("Hello, world!\n")
如果你想写入二进制数据,使用'wb'模式:
with open('example.bin', 'wb') as file:
file.write(b"Hello, world!\n")注意,在'wb'模式下,写入的字符串前需要加上b前缀,表示这是一个字节对象。
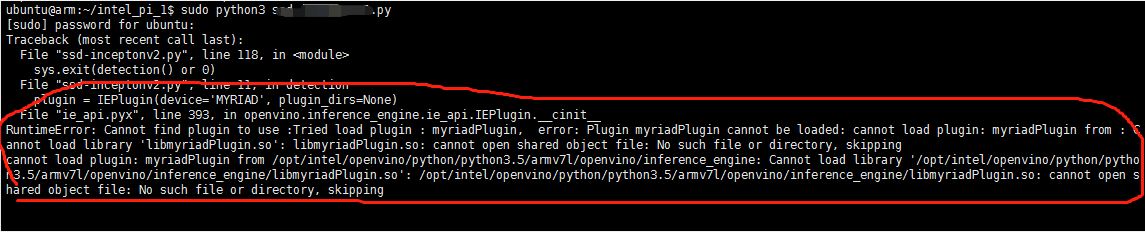
写代码的时候发现一个问题,如下错误

这个错误通常发生在尝试将字符串用于需要字节对象的操作时。在Python 3中,当你以二进制模式(‘b’)打开文件时,所有从文件中读取的数据都会作为字节对象返回,而不是字符串。如果你尝试使用字符串来进行包含测试或其他操作,就会遇到这个错误。
例如,如果你有以下代码:
with open(fname, 'rb') as f:
lines = [x.strip() for x in f.readlines()]
for line in lines:
if 'some-pattern' in line:
continue在这个例子中,因为文件是以二进制模式打开的(‘rb’),所以line是一个字节对象。当你尝试检查'some-pattern'是否在line中时,你需要确保'some-pattern'也是一个字节对象,像这样:
if b'some-pattern' in line:
continue或者,你可以在打开文件时不使用二进制模式,这样读取的内容就会是字符串:
with open(fname, 'r') as f:
lines = [x.strip() for x in f.readlines()]这样,lines中的每一行都是一个字符串,你可以像平常一样使用它们。如果你正在处理网络请求或其他二进制数据,确保在需要字符串的地方使用.decode()方法将字节解码为字符串,或者在需要字节的地方使用.encode()方法将字符串编码为字节。
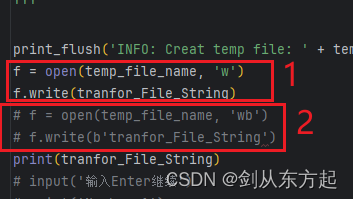
根据上述方式修改一下就行了,两种方式
4、Python里面\与\\的区别
\ 是一个转义字符,用于插入那些字符本身有特殊意义的字符,如引号、问号等。例如,如果你想在字符串中包含一个双引号,你需要使用 \ 来转义它:
print("这是一个包含\"双引号\"的字符串")
输出将是:这是一个包含"双引号"的字符串
\\ 实际上是一个转义序列,用于表示一个字面上的反斜杠。因为 \ 本身是一个转义字符,所以你需要两个反斜杠 \\ 来表示一个字面上的反斜杠。例如,如果你想在路径中使用反斜杠,你应该这样写:
path = "C:\\Users\\Username\\Documents"
这样,path 变量中的字符串将包含字面上的反斜杠。
在处理文件路径时,建议使用原始字符串(在字符串前加 r),这样就不需要转义反斜杠了:
path = r"C:\Users\Username\Documents"
这样写更简洁,也更易于阅读。